Setup Pre-annotator
The pre-annotator is an agent running in the background to make a best guess of un-reviewed data before human annotators start to annotate the samples. A good preannotator can potentially speed up annotation process and improve annotation quality.
SmartAnno uses adaptive models in the backend to complete the pre-annotations:
- At the beginning of the annotation, it uses rule-base pre-annotator (built on top of the ConText algorithm), which can efficiently rule out negated samples.
- After annotators complete some annotations, it will switch to using a machine-learning-based model to complete the pre-annotations. This machine learning-based-model can be replaced or customized, as long as it follows the required interface
Configure rule-based pre-annotator
At the beginning, you will need to configure this rule-based pre-annotator by adding keywords to each annotation type. 
The UMLS-based synonym expander
If you have configured UMLS API key, you can now use UMLS- provided REST service to expand your keywords.
First, you can select which keywords you want to discover using embedding: 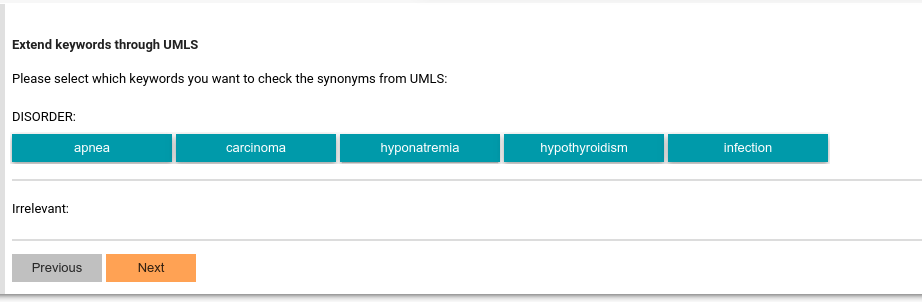
Then you will be prompted to choose which candidates are the synonyms to the selected keywords: 
Note: Because UMLS REST service is internet-based and the service can be overwhelmed by too many requests, you will often encounter lag when using this UMLS-based synonym expander.
The Word-embedding-based related term expander
If you have configured the word embedding model, you can now use the embedding model to expand your keywords.
First, you can select which keywords you want to discover using embedding: 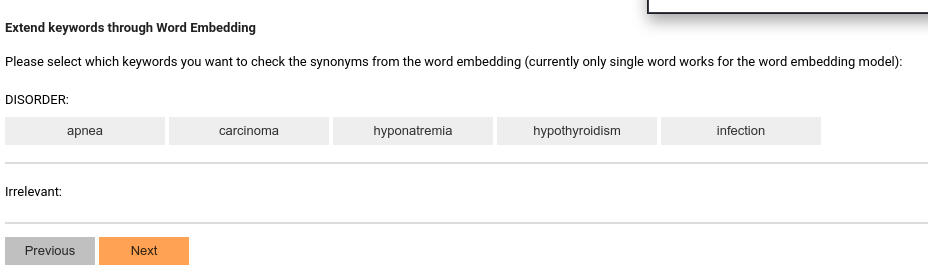
Then you will be prompted to choose which candidates are relevant to the selected keywords: 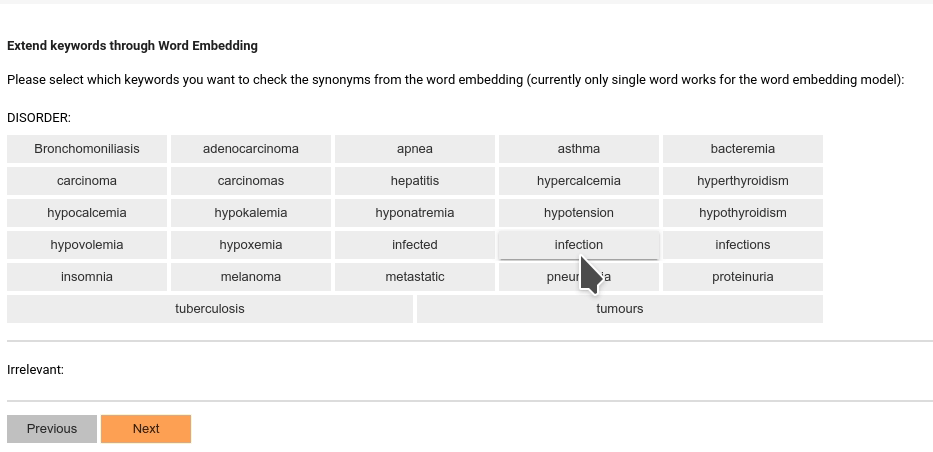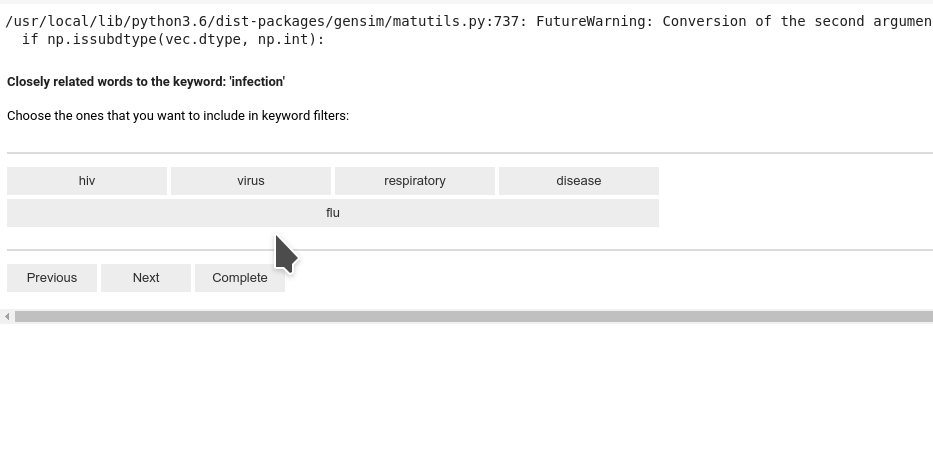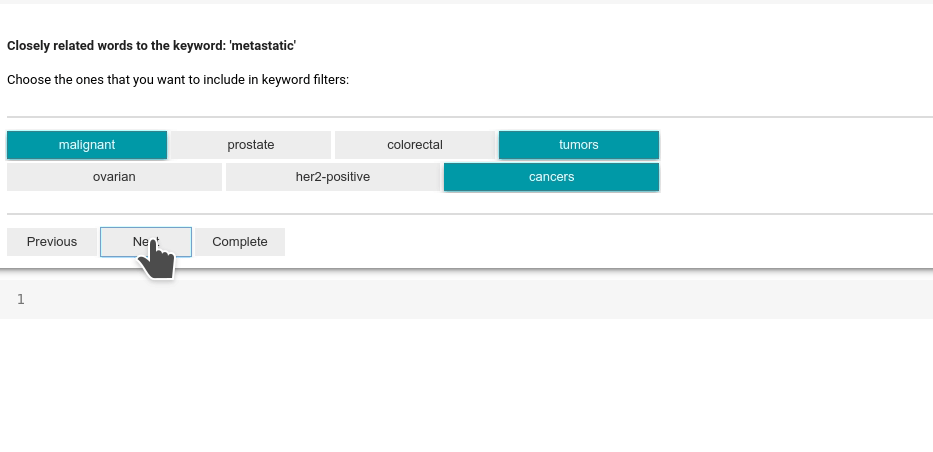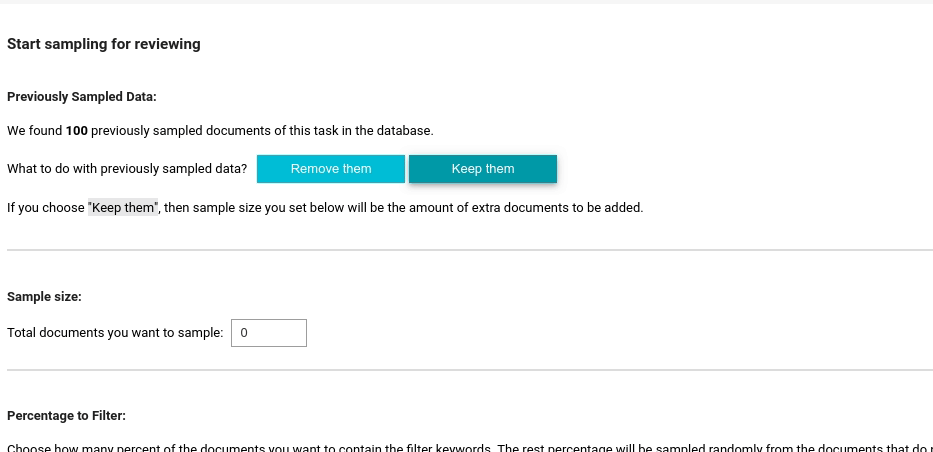
SmartAnno will automatically merge the duplicated keywords. All these keywords will be used to pre-annotate the incoming samples.
Machine-learning-based pre-annotator
The machine-learning-based pre-annotator will be configured after some manual annotations are completed.