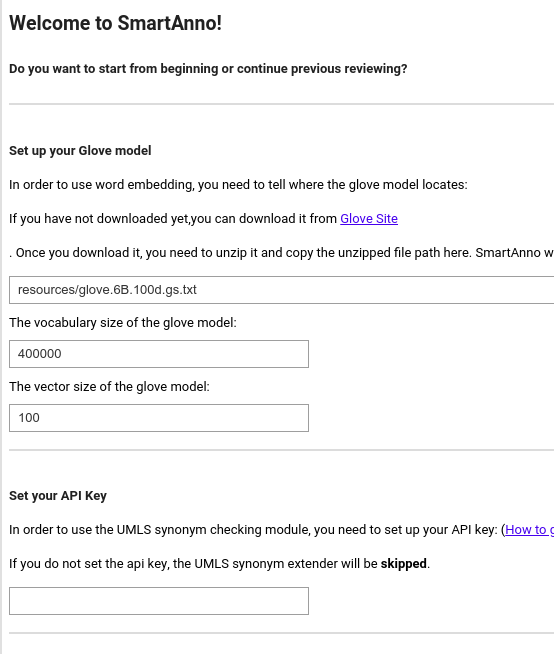
Configure SmartAnno
Configure word embedding model
Because SmartAnno’s current backend models use word embedding, we need to configure where to get the pretrained embedding model, and its vocabulary size and dimension size.
If you directly downloaded Glove embedding, you will need to use gensim to convert the format first as below
from gensim.scripts.glove2word2vec import glove2word2vec
# suppose 'resources/glove.6B.100d.txt' is the embedding file to be converted
glove2word2vec('resources/glove.6B.100d.txt', 'resources/glove.6B.100d.gs.txt')
Then you can check its vocabulary and dimension size using following command (linux):
head -1 resources/glove.6B.100d.gs.txt
The first number is the vocabulary size, the second is the dimension size.
Additional tranformer models will be available soon.
Configure UMLS API key
We can use UMLS REST API to expand keywords by looking for synonyms. These keywords are used in the initial rule-based pre-annotator.
Here is the instruction video about how to get an UMLS API key (at 01:12 from the beginning)
We can also leave it blank if we don’t want to use UMLS.
Configure SmartAnno
With the information above, we are now able to configure SmartAnno:
For more details, please refer to this runnable Colab Notebook.